Zuvor gelesene Blogs:
-
Emily Bache: Iterative and Incremental TDD with the Diamond Kata
Meine Vorgehensweise
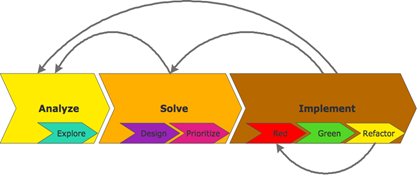
Um das Problem zu verstehen, habe ich selbst diese Kata vorab mittels Flow-Design entworfen. Zuvor habe ich das Problem genau unter die Lupe genommen, heißt ich habe anhand von Beispielen (mittels Papier und Bleistift) nach notwendiger Funktionalität gesucht. Dann habe ich mein Flow-Design erstellt. So stelle ich mir also eine Lösung des Problems vor.

Testfälle zu finden war aufgrund des einfachen Problems, nicht wirklich schwierig. „A“ als Input stellt IMHO den einzigen Sonderfall dar (keine Leerzeichen notwendig). Um die Implementierung voranzutreiben, waren nach „A“, zuerst „B“ und dann „C“ als Input sinnvoll. Das war es allerdings auch schon an priorisierten Testfällen.
Dann habe ich mit der Implementierung des ersten Testfalls („A“) begonnen und ein Walking Skeleton basierend auf meinem Flow-Design erstellt. Das einfache zurückgeben von „A“ (hartcodiert), erschien zu wenig, jedoch für die Implementierung des Grundgerüsts eine gute Hilfe um sicherzustellen, dass die Daten durch alle Methoden fließen. D.h. ich habe das „A“ vom Input durch mein Walking Skeleton zum Output fließen lassen.

Somit war der erste Test auf Grün und das Grundgerüst platziert. Man sieht, mein Flow-Design entspricht genau der Implementierung. In diesem Fall war die Implementierung reines Handwerk und daher schnell getippt. Kreativ war ich beim Flow-Design, hier wurde also Ingenieurstätigkeit von mir erbracht.
Mein nächster Testfall war der Input „B“. Dafür war es notwendig, den nächsten Teil des Walking Skeleton zu implementieren:
Walking Skeleton für Testfall „B“

Jetzt hätte ich mittels Informed TDD die Methoden die derzeit noch nicht implementiert waren, jede für sich umsetzen können. Erschien mir allerdings zu viel Aufwand für das einfache Problem zu sein. Hier hätte man mit Sicherheit in kleineren Schritten vorgehen können.

Ich muss gestehen, hier habe ich einmal auf einen Commit vergessen. Ich habe Prepend_Spaces_To() und Append_Spaces_To() in eine Methode zusammengefügt, da die Implementierungen fast ident waren. Dabei war der Test für den Input „B“ bereits zuvor auf Grün. Somit handelte es sich um ein legitimes Refactoring. Außerdem sind zwei Hilfsfunktionen hinzugekommen, um die notwendigen Leerzeichen zu erzeugen. IMHO handelt es sich dabei um Designdetails, die ich in der Phase des Flow-Design nicht entdeckt habe (was jedoch OK ist).
Die in der Skizze mit Refactoring gekennzeichneten Änderungen im Flow-Design nachgezogen. Es handelt sich also um die zweite Version meines Flow-Designs:

Mein letzter Testfall „C“ sollte eigentlich aufgrund der bis dahin implementierten Funktionalität sofort auf Grün laufen. Allerdings hatte ich einen Fehler in meiner Implementierung der Methode zur Erstellung der Leerzeichen, die in der Mitte von Buchstaben injiziert werden.
Behebung des Fehlers von Leerzeichen

Aufgrund der Kompaktheit und Verständlichkeit der Methode, war die Fehlerbehebung allerdings trivial. Zuletzt habe ich noch ein paar Umbenennungen durchgeführt, und Parameternamen hinzugefügt, um die Verständlichkeit zu erhöhen. Hinzufügen von neuer Funktionalität war zu diesem Zeitpunkt nicht mehr notwendig.
Soweit ich die von mir weiter oben erwähnten Blog-Posts verstanden habe, hat Seb Rose des Öfteren das Problem, dass seine Testfälle zu grobgranular sind, d.h. zu viel an Implementierung erfordern, bis sie tatsächlich auf Grün sind. Somit ändert er kontinuierlich bestehende Testfälle, damit er kleinere Schritte in seiner Implementierung vornehmen kann. Diese Testfälle sind dann letztendlich in der finalen Version nicht mehr sichtbar.
IMHO entspricht das in etwa dem „Informed TDD„-Gedanken. D.h., nachdem meine Walking Skeletons auf Grün waren, hätte ich eigene Testfälle für diese Funktionseinheiten entwerfen können. Dabei hätte ich jeweils immer nur eine Methode implementiert und die jeweils anderen ge-stubbed. Natürlich könnte man auch die Integrationsfunktion Insert_Spaces() in eine eigene Klasse verschieben. Diese hätte dann ebenfalls isoliert getestet werden können.
Was mir beim Flow-Design außerordentlich gut gefällt, ist das umgesetzte Integration Operation Segregation Principle (IOSP). Ausschließlich in den grün gekennzeichneten Funktionseinheiten ist Logik enthalten (if-Statements, etc.). Integrationsmethoden machen nichts anderes, als andere Funktionseinheiten zusammenzufügen. Operationseinheiten haben absolut keine Abhängigkeiten auf andere Operationen. Ausschließlich Integrationen haben Abhängigkeiten.
Hier sieht man die Version von Seb Rose. Was auffällt, in dieser Implementierung wird nicht zwischen Integration und Operation getrennt. Ich hätte sogar gesagt, dass hier eine Operation (Create()) von einer Integration (BuildLine()) abhängt. Operationen sollten jedoch als Blätter in einem Baum implementiert werden, sofern man das IOSP umsetzen möchte.
Ich möchte hier nicht alle Vorteile von Flow-Design, IOSP und Informed TDD aufzählen. Das kann Ralf Westphal natürlich viel besser. Ich empfehle daher sowohl seinen englischen, als auch seinen deutschen Blog nach diesen Themen zu durchsuchen. Auch seine Bücher sind natürlich eine spitzen Quelle, um sich intensiver mit der Thematik zu beschäftigen.
Hier noch die endgültige Version von meiner Lösung:
| using System; | |
| using System.Collections.Generic; | |
| using System.Linq; | |
| namespace domain | |
| { | |
| public class Diamond_Builder | |
| { | |
| private const string NEW_LINE = " | |
| "; | |
| private const char WHITE_SPACE = ' '; | |
| private static readonly List<string> alphabet = new List<string> | |
| { | |
| "A", | |
| "B", | |
| "C", | |
| "D", | |
| "E", | |
| "F", | |
| "G", | |
| "H", | |
| "I", | |
| "J", | |
| "K", | |
| "L", | |
| "M", | |
| "N", | |
| "O", | |
| "P", | |
| "Q", | |
| "R", | |
| "S", | |
| "T", | |
| "U", | |
| "V", | |
| "W", | |
| "X", | |
| "Y", | |
| "Z" | |
| }; | |
| public string Build_Diamond(string middle_letter) | |
| { | |
| var letters = Get_Necessary_Letters(last_letter: middle_letter); | |
| var letters_with_spaces = Insert_Spaces(letters); | |
| var diamond = Duplicate_First_Half_of_Diamond(half_diamond: letters_with_spaces); | |
| var result_diamond = To_String(diamond); | |
| return result_diamond; | |
| } | |
| private List<string> Get_Necessary_Letters(string last_letter) | |
| { | |
| var index_of_last_letter = alphabet.IndexOf(last_letter); | |
| var letters = alphabet.Take(count: index_of_last_letter + 1).ToList(); | |
| var correct_nr_of_letters = letters | |
| .Where(l => l != "A") | |
| .Select(l => l + l) | |
| .ToList(); | |
| correct_nr_of_letters.Insert(0, "A"); | |
| return correct_nr_of_letters; | |
| } | |
| private List<string> Insert_Spaces(List<string> letters) | |
| { | |
| var letters_with_left_and_right_spaces = Add_Left_And_Right_Spaces_To(letters); | |
| var letters_with_spaces = Inject_Spaces_in_the_Middle(letters_with_left_and_right_spaces); | |
| return letters_with_spaces; | |
| } | |
| private List<string> Add_Left_And_Right_Spaces_To(List<string> letters) | |
| { | |
| var spaces = Create_Spaces_For(letters); | |
| var letters_with_prepended_spaces = letters | |
| .Zip(spaces, (l, s) => s + l + s) | |
| .ToList(); | |
| return letters_with_prepended_spaces; | |
| } | |
| private IEnumerable<string> Create_Spaces_For(IReadOnlyCollection<string> letters) | |
| { | |
| var spaces = new List<string>(); | |
| for (var i = letters.Count - 1; i > 0; i--) | |
| spaces.Add(new String(WHITE_SPACE, count: i)); | |
| spaces.Add(""); | |
| return spaces; | |
| } | |
| private List<string> Inject_Spaces_in_the_Middle(List<string> letters) | |
| { | |
| var spaces = Create_Middle_Spaces_For(letters); | |
| var letters_with_middle_spaces = letters | |
| .Zip(spaces, (l, s) => l.Insert(startIndex: (l.Count() / 2), value: s)) | |
| .ToList(); | |
| return letters_with_middle_spaces; | |
| } | |
| private IEnumerable<string> Create_Middle_Spaces_For(List<string> letters) | |
| { | |
| var spaces = new List<string> { "" }; | |
| var odd_nr = 1; | |
| letters.ForEach(l => | |
| { | |
| spaces.Add(new String(WHITE_SPACE, count: odd_nr)); | |
| odd_nr += 2; | |
| }); | |
| return spaces; | |
| } | |
| private IEnumerable<string> Duplicate_First_Half_of_Diamond(List<string> half_diamond) | |
| { | |
| var duplicate = half_diamond | |
| .Take(count: half_diamond.Count - 1) | |
| .ToList(); | |
| duplicate.Reverse(); | |
| half_diamond.AddRange(duplicate); | |
| return half_diamond; | |
| } | |
| private string To_String(IEnumerable<string> diamond) | |
| { | |
| return string.Join(separator: NEW_LINE, values: diamond); | |
| } | |
| } | |
| } |